FraudShield: Bringing Large Language Models to the Edge
Project Overview
The growth of mobile financial transactions has led to a surge in sophisticated SMS fraud ("smishing"). Traditional rule-based filters often miss these evolving threats, while powerful Cloud AI solutions raise serious privacy concerns—users do not want their private banking messages sent to a third-party server.
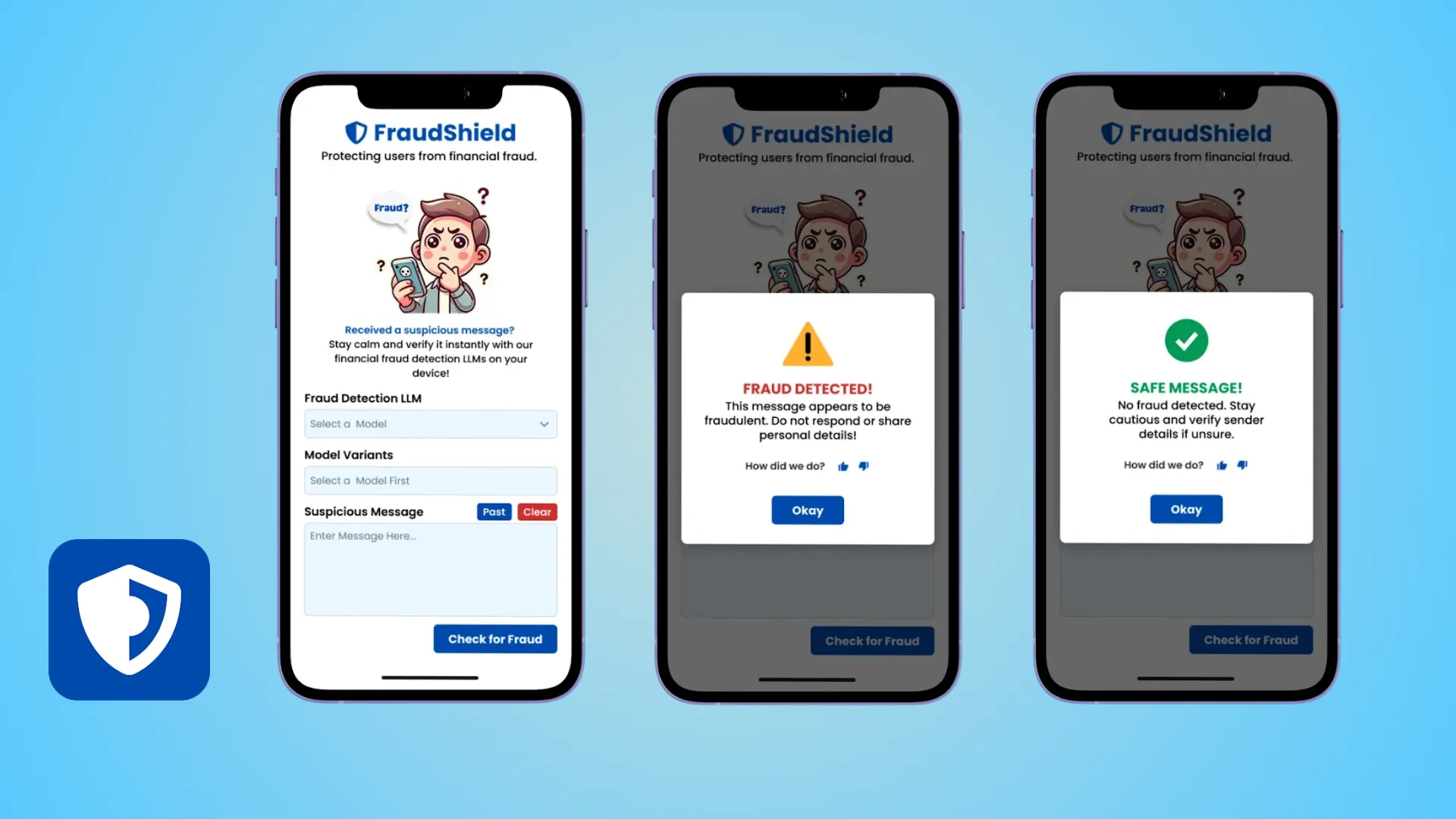
FraudShield is our answer to this dilemma. It is a lightweight mobile application that runs Large Language Models (LLMs) entirely on-device. By optimizing and compressing advanced AI models, we achieved 99.5% fraud detection accuracy in an offline environment, ensuring user data never leaves their phone.
The Challenge
Deploying GenAI for security presented a "Trilemma" of conflicting constraints:
1. The Privacy Barrier
Financial text messages contain sensitive personal data (OTP codes, balance alerts). Sending this data to a cloud API (like OpenAI) for analysis is a security risk and a privacy violation. The solution had to work 100% offline.
2. The Resource Gap
Standard LLMs require gigabytes of RAM and powerful GPUs. Running them on a standard smartphone usually drains the battery instantly or crashes the device.
3. Real-Time Latency
Fraud happens in seconds. A user might click a phishing link immediately. We couldn't afford the latency of network calls; the detection needed to happen in milliseconds.
Our Solution: Extreme Model Quantization
We moved the intelligence from the server to the pocket. Instead of building a simple app wrapper, we engaged in deep Machine Learning engineering to fine-tune and shrink open-source models.
Phase 1: Model Optimization & Fine-Tuning
We selected compact "Small Language Models" (SLMs)—specifically Llama-160M and Qwen1.5-0.5B. We fine-tuned these models on a curated dataset of financial fraud messages, teaching them to recognize subtle linguistic patterns used by scammers (urgency, fake authority, suspicious links).
Phase 2: Quantization & Compression
To fit these models on a phone, we utilized 4-bit quantization and converted them to the ONNX (Open Neural Network Exchange) format.
- Drastic Size Reduction: We compressed the Llama-160M model down to a mere 168MB footprint.
- Efficiency: This allowed the model to load into the RAM of even mid-range Android devices without affecting performance.
Phase 3: The Mobile Guardian
We built a React Native interface that runs the ONNX model in the background. It intercepts incoming SMS, tokenizes the text locally, infers the probability of fraud, and alerts the user—all within a fraction of a second.
Key Features
🛡️ 100% Offline Privacy
No internet connection is required for detection. Your messages are processed on your device's CPU/NPU, ensuring absolute data sovereignty. No data is ever uploaded to the cloud.
⚡ Sub-Second Inference
By using ONNX Runtime, the app delivers near-instant analysis. Users are warned about a "Suspicious Transaction Alert" before they even finish reading the message.
🧠 Context-Aware Understanding
Unlike keyword blockers (which block anything saying "Bank"), the LLM understands context. It can distinguish between a legitimate "Your balance is low" alert from your actual bank and a fake "URGENT: UPDATE DETAILS" phishing attempt.
Technical Implementation
Tech Stack
- Core AI: Fine-tuned Llama-160M & Qwen1.5-0.5B models.
- Model format: ONNX (Open Neural Network Exchange) for cross-platform hardware acceleration.
- Mobile Framework: React Native with a custom C++ bridge for the inference engine.
- Training: PyTorch with QLoRA (Quantized Low-Rank Adaptation) for efficient fine-tuning.
Comparative Performance Data
We tested multiple model architectures to find the perfect balance of speed vs. accuracy.
| Model Variant | Quantization | Accuracy | Model Size |
|---|---|---|---|
| Llama-160M-Chat | 4-bit (bnb4) | 99.47% | 168 MB |
| Qwen1.5-0.5B-Chat | 4-bit (bnb4) | 99.50% | 797 MB |
The Llama-160M variant proved to be the "sweet spot," delivering enterprise-grade security with a footprint smaller than a typical social media app.
Results & Impact
FraudShield demonstrates that privacy and AI power can coexist.
- 99.47% Detection Accuracy: Outperformed traditional keyword-based filters by a significant margin.
- Zero Data Leakage: Successfully validated that no data packets leave the device during the scanning process.
- Battery Efficient: The optimized model consumes negligible battery power, running only when a message arrives.
- Featherweight Footprint: At just ~170MB, the full AI engine is light enough for mass adoption in emerging markets with older devices.
Conclusion
FraudShield is more than an app; it is a proof of concept for the future of Edge AI. CodeScale has proven that we can take massive, complex Large Language Models and engineer them to solve real-world problems on the most constrained devices, bringing the power of AI to users without compromising their privacy.